K8s-网络模型
K8s-网络模型
K8s场景网络主要有以下几种:
- Container-to-Container网络
- Pod-to-Pod网络
- Pod-to-Service网络
- Internet-to- Service网络
Container-to-Container网络
虚拟机网络:
在Linux 系统中,其实本质上在network namespace通信,每一个network namespace提供逻辑的网络堆栈,创建的namespace,会被挂载到/var/run/netns
# 添加一个network namespace |
默认情况下,Linux所有的进程都被分配到root network namespace
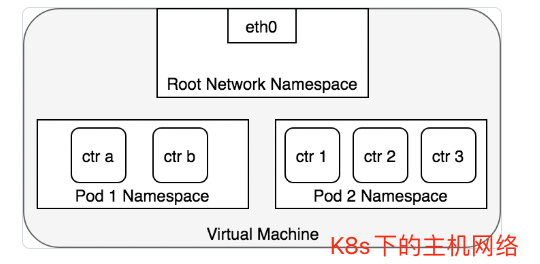
在K8s网络下,所有Pod下的容器共享一个网络:
- 在这个network namespace下使用同一个IP和同一个端口空间
- 通过localhost自然也可以访问Pod下的其他容器
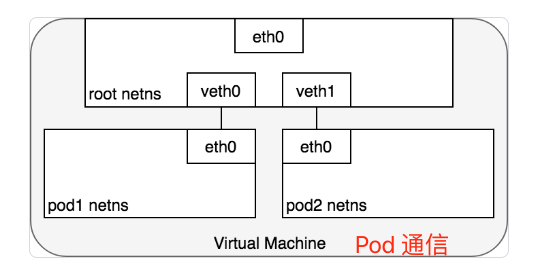
Pod-to-Pod的网络
Pod和Pod之间的通信,其实就是把Pod网络 通过veth pair|Virtual Ethernet Device 实现通信。
Linux Ethernet bridge 是一个虚拟的 Layer 2 网络设备,可用来连接两个或多个网段(network segment)。网桥的工作原理是,在源于目标之间维护一个转发表(forwarding table),通过检查通过网桥的数据包的目标地址(destination)和该转发表来决定是否将数据包转发到与网桥相连的另一个网段。桥接代码通过网络中具备唯一性的网卡MAC地址来判断是否桥接或丢弃数据。
网桥实现了 ARP (opens new window)协议,以发现链路层与 IP 地址绑定的 MAC 地址。当网桥收到数据帧时,网桥将该数据帧广播到所有连接的设备上(除了发送者以外),对该数据帧做出相应的设备被记录到一个查找表中(lookup table)。后续网桥再收到发向同一个 IP 地址的流量时,将使用查找表(lookup table)来找到对应的 MAC 地址,并转发数据包。
Pod同节点
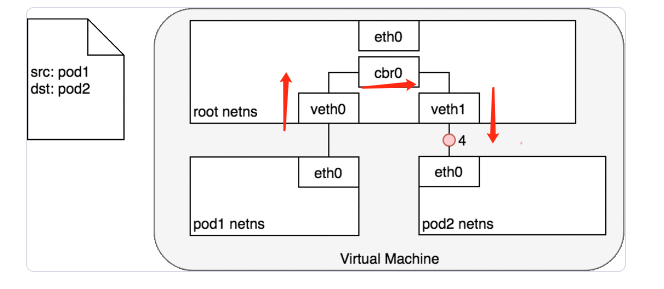
数据包发送流程:
- Pod1发送数据包到自己默认以太网设备
etho0 - Pod1,通过虚拟以太网设备
veth0连接到root namespace - 网桥
cbr0中veth0配置了网段。数据包到达网桥之后,网桥通过ARP协议解析目标网段为veth1 cbr0转发数据包到veth1- 数据包到达
veth1,数据包转发到Pod2的etho网络设备
Pod跨节点
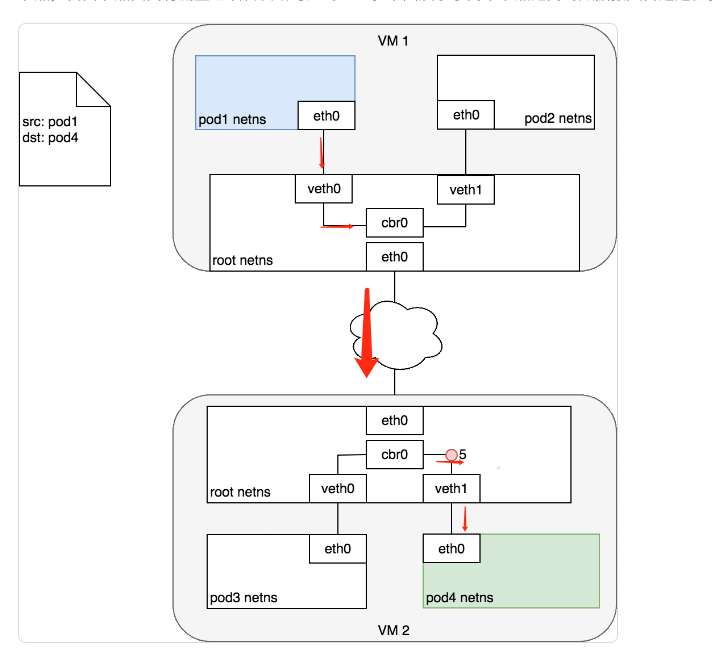
数据包发送流程:
- 数据包从Pod1的
eth0连接到root namespace - 数据包到达网络
cbr0 - 网桥上执行ARP,但是网桥连接设备解析不到数据包匹配的Mac地址。ARP失败之后,网桥把数据包转发给root namespace的
eth0设备 - 数据包通过节点CIDR网段,寻找到正确节点
- 数据包进入目标节点的root namespace(VM2的
eth0),然后通过虚拟网桥找到虚拟设备veth1 - 数据包通过
veth1发送路由到Pod4目标的eth0
Container Network Interface(CNI) plugin 提供了一组通用 API 用来连接容器与外部网络
Pod-to-Service网络
Pod to Pod的网络已经解决了,但是K8s引入了Service,因为Pod的IP上会经常变化的
netfilter and iptables
Kubernetes 利用 Linux 内建的网络框架 - netfilter 来实现负载均衡。Netfilter 是由 Linux 提供的一个框架,可以通过自定义 handler 的方式来实现多种网络相关的操作。Netfilter 提供了许多用于数据包过滤、网络地址转换、端口转换的功能,通过这些功能,自定义的 handler 可以在网络上转发数据包、禁止数据包发送到敏感的地址,等。
iptables 是一个 user-space 应用程序,可以提供基于决策表的规则系统,以使用 netfilter 操作或转换数据包。在 Kubernetes 中,kube-proxy 控制器监听 apiserver 中的变化,并配置 iptables 规则。当 Service 或 Pod 发生变化时(例如 Service 被分配了 IP 地址,或者新的 Pod 被关联到 Service),kube-proxy 控制器将更新 iptables 规则,以便将发送到 Service 的数据包正确地路由到其后端 Pod 上。iptables 规则将监听所有发向 Service 的虚拟 IP 的数据包,并将这些数据包转发到该Service 对应的一个随机的可用 Pod 的 IP 地址,同时 iptables 规则将修改数据包的目标 IP 地址(从 Service 的 IP 地址修改为选中的 Pod 的 IP 地址)。当 Pod 被创建或者被终止时,iptables 的规则也被对应的修改。换句话说,iptables 承担了从 Service IP 地址到实际 Pod IP 地址的负载均衡的工作。
在返回数据包的路径上,数据包从目标 Pod 发出,此时,iptables 规则又将数据包的 IP 头从 Pod 的 IP 地址替换为 Service 的 IP 地址。从请求的发起方来看,就好像始终只是在和 Service 的 IP 地址通信一样
IPVS
Kubernetes v1.11 开始,提供了另一个选择用来实现集群内部的负载均衡:IPVS。 IPVS(IP Virtual Server)也是基于 netfilter 构建的,在 Linux 内核中实现了传输层的负载均衡。IPVS 被合并到 LVS(Linux Virtual Server)当中,充当一组服务器的负载均衡器。IPVS 可以转发 TCP / UDP 请求到实际的服务器上,使得一组实际的服务器看起来像是只通过一个单一 IP 地址访问的服务一样。IPVS 的这个特点天然适合与用在 Kubernetes Service 的这个场景下。
当声明一个 Kubernetes Service 时,你可以指定是使用 iptables 还是 IPVS 来提供集群内的负载均衡工鞥呢。IPVS 是转为负载均衡设计的,并且使用更加有效率的数据结构(hash tables),相较于 iptables,可以支持更大数量的网络规模。当创建使用 IPVS 形式的 Service 时,Kubernetes 执行了如下三个操作:
- 在节点上创建一个 dummy IPVS interface
- 将 Service 的 IP 地址绑定到该 dummy IPVS interface
- 为每一个 Service IP 地址创建 IPVS 服务器
将来,IPVS 有可能成为 kubernetes 中默认的集群内负载均衡方式。这个改变将只影响到集群内的负载均衡,本文后续讨论将以 iptables 为例子,所有讨论对 IPVS 是同样适用的。
数据包:Pod-to-Service
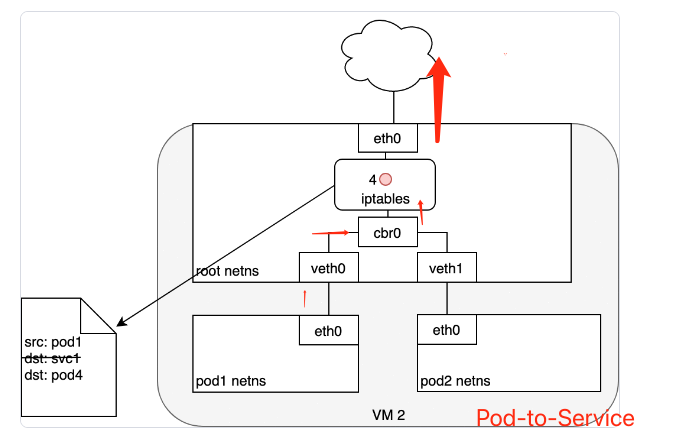
数据包传输过程:
数据包通过Pod的
eth0到达root namespace的veth0数据包通过
veth0到达虚拟网桥cbr0网桥的ARP协议找不到Service,数据包转发到root namespace 的
eth0数据包在到达
erh0,进行iptables过滤,此时通过iptables(由kube-proxy根据Service、Pod的变化创建iptables),重新目标地址为PodIP现在数据包可以通过Pod-to-Pod进行访问了。ptables 使用 Linux 内核的
conntrack工具包来记录具体选择了哪一个 Pod,以便可以将未来的数据包路由到同一个 Pod。简而言之,iptables 直接在节点上完成了集群内负载均衡的功能
数据包:Service-to-Pod
- Service先找到发送源的Pod IP
- 数据包的源IP从ServiceIP转化为真实的发送请求Pod IP
- 进行Pod-to-Pod访问
DNS
Kubernetes 也可以使用 DNS,以避免将 Service 的 cluster IP 地址硬编码到应用程序当中。Kubernetes DNS 是 Kubernetes 上运行的一个普通的 Service。每一个节点上的 kubelet 都使用该 DNS Service 来执行 DNS 名称的解析。集群中每一个 Service(包括 DNS Service 自己)都被分配了一个 DNS 名称。DNS 记录将 DNS 名称解析到 Service 的 ClusterIP 或者 Pod 的 IP 地址。SRV 记录 用来指定 Service 的已命名端口。
DNS Pod 由三个不同的容器组成:
kubedns:观察 Kubernetes master 上 Service 和 Endpoints 的变化,并维护内存中的 DNS 查找表dnsmasq:添加 DNS 缓存,以提高性能sidecar:提供一个健康检查端点,可以检查dnsmasq和kubedns的健康状态
DNS Pod 被暴露为 Kubernetes 中的一个 Service,该 Service 及其 ClusterIP 在每一个容器启动时都被传递到容器中(环境变量及 /etc/resolves),因此,每一个容器都可以正确的解析 DNS。DNS 条目最终由 kubedns 解析,kubedns 将 DNS 的所有信息都维护在内存中。etcd 中存储了集群的所有状态,kubedns 在必要的时候将 etcd 中的 key-value 信息转化为 DNS 条目信息,以重建内存中的 DNS 查找表。
CoreDNS 的工作方式与 kubedns 类似,但是通过插件化的架构构建,因而灵活性更强。自 Kubernetes v1.11 开始,CoreDNS 是 Kubernetes 中默认的 DNS 实现。
Internet-to-Service的网络
出:集群内部到互联网
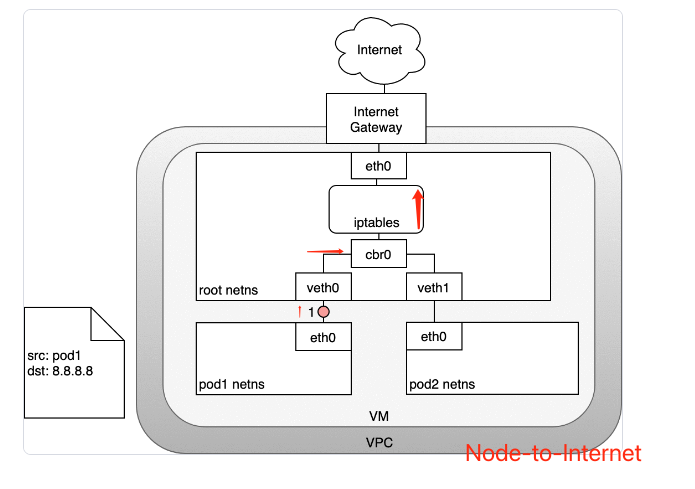
数据包的传递:Node-to-Internet
- 数据包从 Pod 的 network namespace 发出
- 通过
veth0到达虚拟机的 root network namespace - 由于网桥上找不到数据包目标地址对应的网段,数据包将被网桥转发到 root network namespace 的网卡
eth0。在数据包到达eth0之前,iptables 将过滤该数据包。 - 在此处,数据包的源地址是一个 Pod,如果仍然使用此源地址,互联网网关将拒绝此数据包,因为其 NAT 只能识别与节点(虚拟机)相连的 IP 地址。因此,需要 iptables 执行源地址转换(source NAT),这样子,对互联网网关来说,该数据包就是从节点(虚拟机)发出的,而不是从 Pod 发出的
- 数据包从节点(虚拟机)发送到互联网网关
- 互联网网关再次执行源地址转换(source NAT),将数据包的源地址从节点(虚拟机)的内网地址修改为网关的外网地址,最终数据包被发送到互联网
入: 从互联网访问Kubernetes
入方向访问(从互联网访问Kubernetes集群)是一个非常棘手的问题。该问题同样跟具体的网络紧密相关,通常来说,入方向访问在不同的网络堆栈上有两个解决方案:
- Service LoadBalancer
- Ingress Controller
LoadBalancer
创建K8s Service 类型指定为LoadBalancer
数据包的传递:LoadBalancer-to-Service
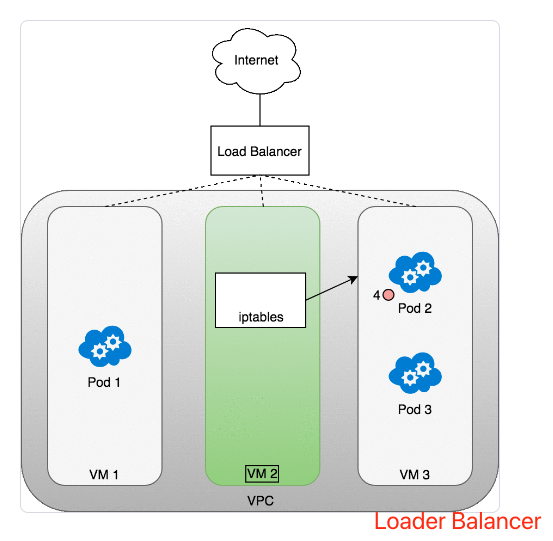
数据包传输过程:
- 请求数据包从互联网发送到负载均衡器
- 负载均衡器将数据包随机分发到其中的一个节点(虚拟机),此处,我们假设数据包被分发到了一个没有对应 Pod 的节点(VM2)上
- 在 VM2 节点上,kube-proxy 在节点上安装的 iptables 规则会将该数据包的目标地址判定到对应的 Pod 上(集群内负载均衡将生效)
- iptables 完成 NAT 映射,并将数据包转发到目标 Pod
Ingress控制器
 alipay
alipay

