Prometheus-接入ETCD监控
Prometheus-接入ETCD监控
Introduce
通过Prometheus监控ETCD数据,包括Grafana
Overview
1 | # 通过2379 获取指标 |
Etcd 中的指标可以分为三大类:
- Server
- Disk
- Netwrok
Server
以下指标前缀为 etcd_server_。
- has_leader:集群是否存在 Leader
- 没有的话集群不可以
- leader_changes_seen_total:leader 切换数
- 比较多的话说明集群不稳定
- proposals_committed_total:已提交提案数
- 如果 member 和 leader 差距较大,说明 member 可能有问题,比如运行比较慢
- proposals_applied_total:已 apply 的提案数
- 已提交提案数和已 apply 提案数差值应该比较小,持续升高则说明 etcd 负载较高
- proposals_pending:等待提交的提案数
- 该值升高说明 etcd 负载较高或者 member 无法提交提案
- proposals_failed_total:失败的提案数
Disk
以下指标前缀为 etcd_disk_。
- wal_fsync_duration_seconds_bucket:反映系统执行 fdatasync 系统调用耗时
- backend_commit_duration_seconds_bucket:提交耗时
Network
以下指标前缀为etcd_network_。
- peer_sent_bytes_total:发送到其他 member 的字节数
- peer_received_bytes_total:从其他 member 收到的字节数
- peer_sent_failures_total: 发送失败数
- peer_received_failures_total:接收失败数
- peer_round_trip_time_seconds:节点间的 RTT
- client_grpc_sent_bytes_total:发送给客户端的字节数
- client_grpc_received_bytes_total:从客户端收到的字节数
核心指标
上面就是 etcd 的所有指标了,其中比较核心的是下面这几个:
- **
etcd_server_has_leader**:etcd 集群是否存在 leader,为 0 则表示不存在 leader,整个集群不可用 - **
etcd_server_leader_changes_seen_total**: etcd 集群累计 leader 切换次数 - **
etcd_disk_wal_fsync_duration_seconds_bucket**:wal fsync 调用耗时,正常应该低于 10ms - **
etcd_disk_backend_commit_duration_seconds_bucket**:db fsync 调用耗时,正常应该低于 120ms - **
etcd_network_peer_round_trip_time_seconds_bucket**:节点间 RTT 时间
Deploy
1⃣️配置Prometheus
1.创建 etcd service & endpoint
对于外置的 etcd 集群,或者以静态 pod 方式启动的 etcd 集群,都不会在 k8s 里创建 service,而 Prometheus 需要根据 service + endpoint 来抓取,因此需要手动创建
1 | cat > etcd-svc-ep.yaml << EOF |
2.创建 secret 存储证书
1 | certs=/etc/kubernetes/pki/etcd/ |
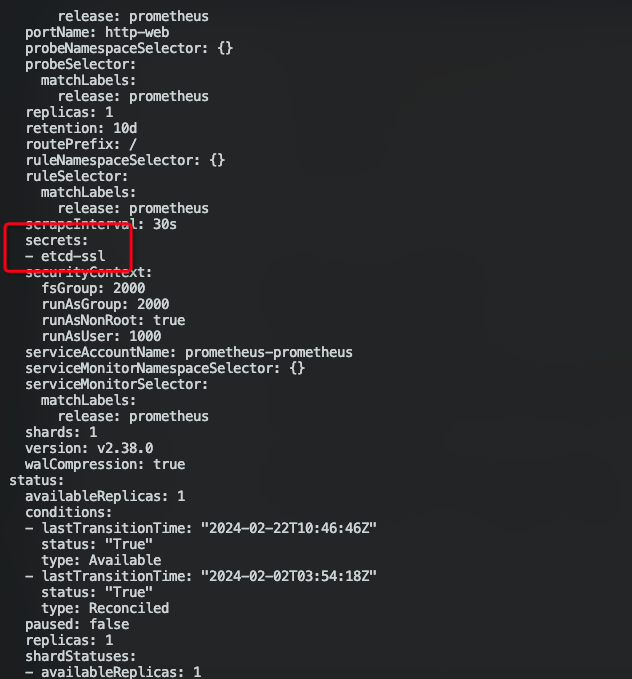
3.将证书挂载至 Prometheus 容器
由于 Prometheus 是 operator 方式部署的,所以只需要修改 prometheus 对象
1 | kubectl -n monitoring edit prometheus prometheus |
4.创建 Etcd ServiceMonitor
接下来则是创建一个 ServiceMonitor 对象,让 Prometheus 去采集 etcd 的指标
1 | cat > etcd-sm.yaml << EOF |
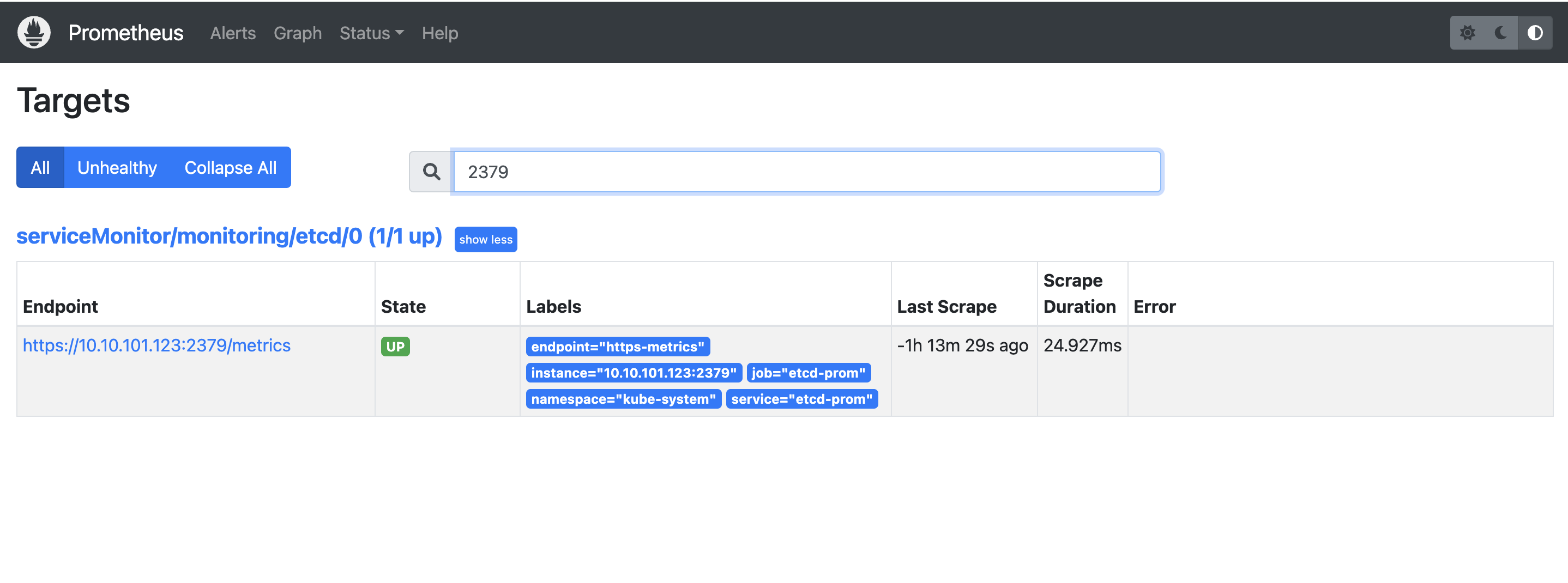
在Prometheus中就能看见这个2379的Target
2⃣️导入Grafana
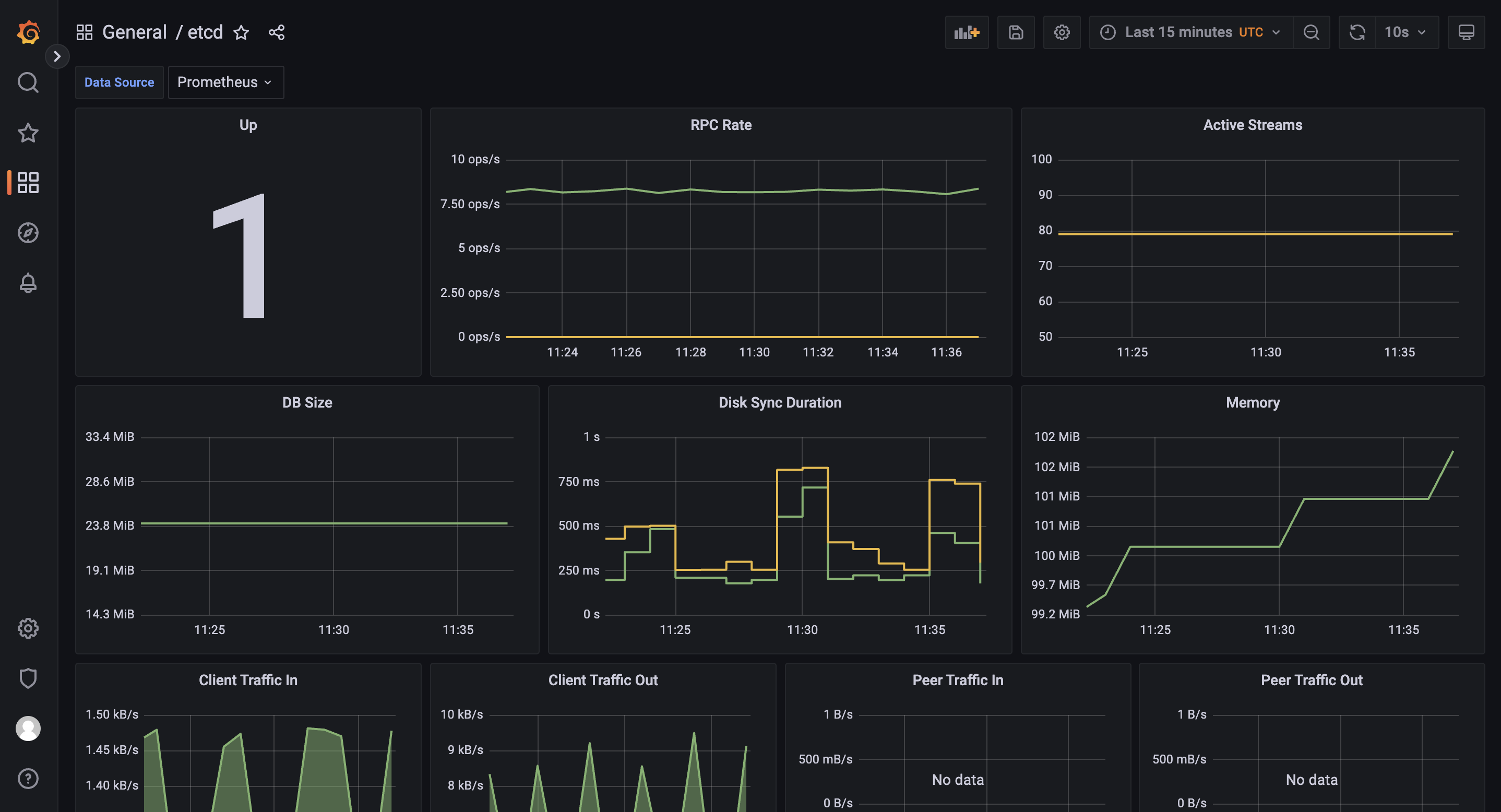
效果:
3⃣️配置告警
对于部分核心指标,建议配置到告警规则里,这样出问题时能及时发现
1 | # these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet |
核心策略
实际上只需要对前面提到的几个核心指标配置上告警规则即可:
sum(up{job=~".\*etcd.\*"} == bool 1) by (job) < ((count(up{job=~".\*etcd.\*"}) by (job) + 1) / 2): 当前存活的 etcd 节点数是否小于 (n+1)/2- 集群中存活小于 (n+1)/2 那么整个集群都会不可用
etcd_server_has_leader{job=~".\*etcd.\*"} == 0:etcd 是否存在leader- 为 0 则表示不存在 leader,同样整个集群不可用
rate(etcd_server_leader_changes_seen_total{job=~".\*etcd.\*"}[15m]) > 3: 15 分钟 内集群leader切换次数是否超过 3 次- 频繁 Leader 切换会影响集群稳定性
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.5:5 分钟内 WAL fsync 调用延迟 p99 大于 500ms- **
histogram_quantile(0.99,rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.25**:5 分钟内 DB fsync *调用延迟 p99 大于 500**ms* histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5: 5 分钟内 节点之间 RTT 大于 500 ms
Yaml:
1 | # these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet |
导入到Prometheus
1 | cat > pr.yaml << "EOF" |
配置prometheus:
1 | kubectl -n monitoring get prometheus |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Joohwan!
 alipay
alipay
相关推荐

2025-09-24
Prometheus源码-Relabel
Prometheus源码-Relabel 基于3.5 relabel address流程 Prometheus读取Job中的targets,把target赋值给__address__标签,此标签代表采集地址 将__address__赋值给__param_target标签,因为Promehrues访问采集地址需要传参,__param_target代表target参数 将__param_target标签赋值给instance标签 将__param_target替换为真实的采集地址 核心解析Label Re123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114// Popul...
2025-08-05
Prometheus-PromQL
Prometheus-PromQL 基于v3.5 工作原理graph TD A[Query Input] --> B[Parser] B --> C[Engine] C --> D[Query Execution] D --> E[Result Output] %% Parser Module subgraph Parser["Parser (parser/)"] B1[Lexical Analysis] --> B2[Syntax Parsing] B2 --> B3[AST Generation] B3 --> B4[Validation] end %% Engine Module subgraph Engine["Engine (engine.go)"] C1[Query Initialization] --> C2[Query Planning]...
2025-07-26
Prometheus-Rules告警评估
Prometheus-Rules告警评估 基于v3.5 工作原理graph TD A[Rule Files] --> B[Manager.LoadGroups] B --> C[Parse Rule Groups] C --> D[Create Rule Objects] D --> E[Analyse Rule Dependencies] E --> F[Build Dependency Map] F --> G[Set Rule Dependencies] H[Manager.Run] --> I[Group Evaluation Loop] I --> J[Split Rules into Batches] J --> K{Concurrent Evaluation Enabled?} K -->|Yes| L[Concurrent Rule Execution] K -->|No| M[S...
2025-07-25
Prometheus-Scrape指标抓取
Prometheus-Scrape指标抓取 基于v3.5 工作原理graph TD A[ScrapePool] --> B[Target Discovery] A --> C[Scrape Loop Management] A --> D[HTTP Client] B --> B1[Sync Targets] B1 --> B2[Target Group Processing] B2 --> B3[Target Creation/Deduplication] B3 --> B4[Active Targets Update] C --> C1[Loop Creation] C1 --> C2[Scrape Interval Setup] C2 --> C3[Scraper Initialization] D --> D1[Target Scraper] D1 --> D2[HTTP Request] D2 --> D3[Metrics Endpoint] C3 -->...
2025-07-24
Prometheus-notifier告警推送
Prometheus-notifier告警推送 基于v3.5 工作原理sequenceDiagram participant Q as Queue participant M as Manager participant AM as Alertmanager participant AL as Alertmanager API Q->>M: nextBatch() M->>M: 分批处理告警 M->>AM: sendAll() AM->>AM: 应用特定于 AM 的 relabel AM->>AL: HTTP POST /api/v2/alerts AL-->>AM: Response AM->>M: 返回发送结果 关键特性 告警队列管理 有界队列,防止内存无限增长 支持队列满时的丢弃策略 可配置的批处理大小 Relabeling(重新标记) 发送前对告警应用 relabel 配置 支持每个 Alertmanager 集合的特定 relabel 规则 高可用性...
2025-07-23
Prometheus-Discoverer服务发现
Prometheus-Discoverer服务发现 基于v3.5 启动流程sequenceDiagram participant main.go participant Manager participant Provider participant Discoverer participant TargetGroup main.go->>Manager: NewManager() main.go->>Manager: ApplyConfig() Manager->>Provider: 创建Provider实例 Manager->>Provider: startProvider() Provider->>Discoverer: 初始化具体发现器(如K8s/Consul等) Provider->>Discoverer: Run(ctx, updatesCh) loop 发现循环 Discoverer->>TargetGroup: 获取目标组 ...
评论
