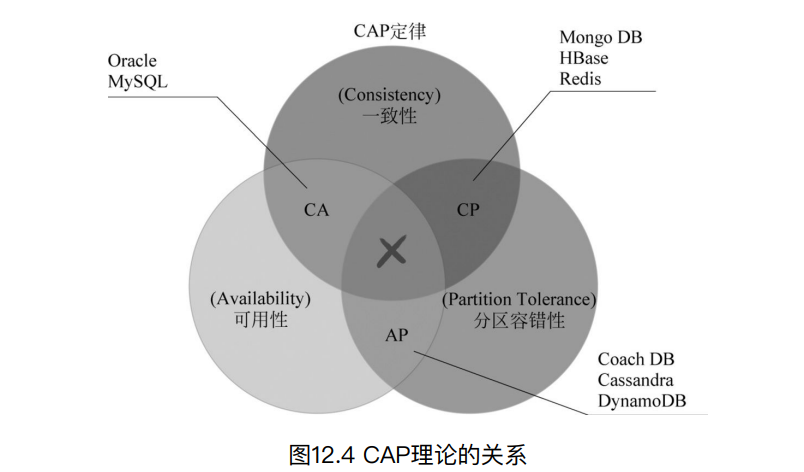
分布式-CAP理论
背景
在大规模拓展服务下存在三个特性:
C(Consistency):一致性
A(Availability):可用性
D(Partition Tolerance):分区容错性
一致性
一致性: All nodes see the same data at the same time
所有节点数据,在同一时刻,读数据都是最新的
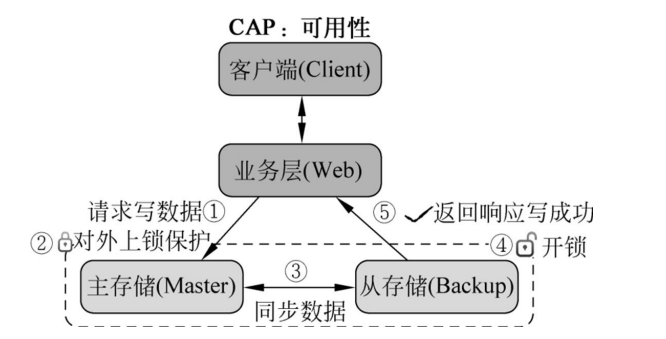
流程:
对主存储写数据
进行上锁,要求对从存储进行同步
同步成功,释放锁,返回成功
可用性
可用性:Reads and writes always succeed
服务永远可用,用户感知不到异常
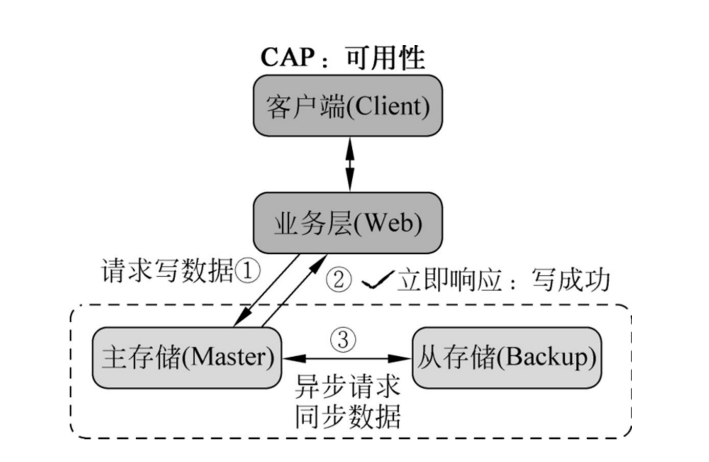
流程:
用户向master请求
master从从存储请求
分区容错性
分区容错性:The system continues to operate despite arbitrary message loss or failure of part of the system
在分布式系统中,尽管部分节点出现任何消息丢失或者故障,系统还应继续运⾏
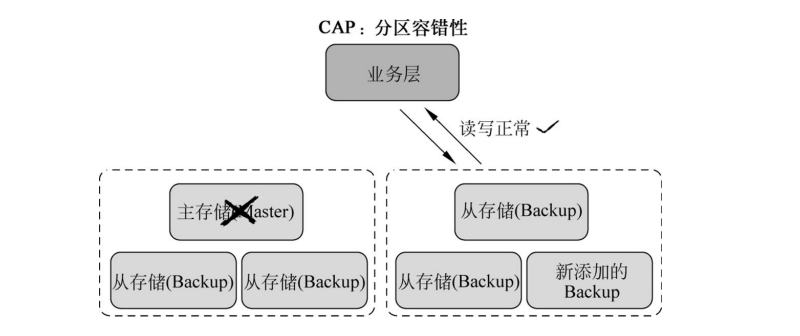
流程:
尽使⽤异步取代同步操作,例如使⽤异步⽅式将数据从主数据库同步到从数据,这样节点
之间能有效地实现松耦合。
CAP的取舍
CAP一般都是只能三选二,其中P应该是分布式系统的必须项目,所以只能在CA中权衡
CP放弃A
CP放弃A,就是允许系统停机和长时间无响应
放弃可⽤性,追求⼀致性和分区容错性,如Redis、HBase等,还有分布式系统中常⽤的
Zookeeper也在CAP三者之中选择优先保证CP。
典型的CP应⽤场景,如跨⾏转账,⼀次转账请求要等待双⽅银⾏系统完成整个事务才算完
成。
AP放弃C
AP放弃C,在某一段时间内无法保持一致性,但是会保持最终一致性
典型的应⽤场景1,如淘宝订单退款。今⽇退款成功,明⽇到账,只要⽤户可以接受在⼀定时
间内到账即可
参考
- 刘丹冰:深入理解Go语言
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Joohwan!
 alipay
alipay
相关推荐

2024-07-23
Go-标准库日志Slog
Go的标准库日志Slog背景在Go1.21中,在Go的标准库函数中引入了Slog 据说使用的内存比Zap还要小 基础用法12345678slog.Info("This is info log")slog.Warn("This is warning log")slog.Error("This is error log")日志输出:2024/07/23 15:26:01 INFO This is info log2024/07/23 15:26:01 WARN This is warning log2024/07/23 15:26:01 ERROR This is error log 输出参数的日志12345678 name := "sss" slog.Info("msg", slog.String("name", name)) slog.Error("ERROR: value is empty", slog.Any("name&qu...
2024-03-31
Go-控制协程数量
Go-控制协程数量背景GMP的无限创建Goroutine基于共享用户态资源,过多的协程会导致CPU利用率浮动上涨、内存占用上涨、主进程崩溃 如何控制Goroutine数量基于buffer的channel原理:通过buffer的缓冲区的大小和阻塞等待来控制最大的数量 1234567891011121314151617181920212223242526package mainimport ( "fmt" "runtime" "time")func doGoroutine(i int, ch chan bool) { fmt.Println("go func", i, "goroutine count", runtime.NumGoroutine()) // 结束了一个任务 <-ch}func main() { task_cnt := 10 // 容量控制了 Goroutine 的数量 ch := make(chan bool, 3) // for的...
2024-03-30
分布式-Base理论
分布式-Base理论介绍CAP无法同时满足,为了同时实现CAP系统,所以出现了BASE BA(Basically Available):基本 可用 S(Soft State):软状态 E(Eventually Consistent):最终一致性 ACID和BASE是对冲理论: ACID追求强一制性 BASE牺牲强一致性,追求高可用性 Basically Available 通过妥协响应时间和功能损失 场景: 断电,增大响应时间 高并发下,电商提示抢购失败 Soft State软状态本质就是系统中的数据有中间状态,多节点的副本数据等待同步数据延迟 Eventually Consistent软状态数据不可以一直持续,必须在一段时间内完成同步,达到最终一致性
2024-03-30
分布式 id 生成器(snowflake,雪花算法)
分布式 id 生成器(snowflake,雪花算法)背景在某些场景下,需要生成增长ID并且不能重复 snowflakeSnowflake 雪花算法,由Twitter提出并开源,可在分布式环境下用于生成唯一ID的算法。该算法生成的是一个64位的ID,故在Java下正好可以通过8字节的long类型存放。所生成的ID结构如下所示 1 bit:首位无效因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。 41 bit:表示的是时间戳,单位是毫秒41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。 10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),也可以根据自己公司的实际情况确定。 12 b...
2024-03-30
ACID理论
ACID理论背景ACID主要是事务中的概念,分别是 A(Atomicit):原子性 C(Consistency):一致性 I(Isolation):隔离性 D(Durability):持久性 A原子性主要是在一个事务中,“要么全部完成、要么全部不完成” 经典的银行转账案例: A:从A账户去一百 B:从存入100 AB是在一个事务里面,不能只有A|B其中一个成功,不然银行账户对不上金额 C一致性一致性代表:事务开始前和事务结束之后,数据库的一致性没有改变,事务中的数据一致性 I隔离性隔离性代表:多个并发事务同时拥有对数据进行读书和修改的能力,如果⼀个事务要访问的数据正在被另外⼀个事务修改,只要另外⼀个事务未提交,则它所访问的数据就不受未提交事务的影响 D持久性持久性代表:事务处理结束后,对数据的修改是永久的,即便系统故障也不会丢失 优点1、数据一致性:ACID 确保数据在任何事务执行后保持一致和准确。 2、数据完整性:ACID 通过确保对数据库的任何更改都是永久性的,并且不会丢失,从而维护了数据的完整性。 3、并发控制:ACID 通过防止事务之间的干扰来帮助管理并发创建的多个事务...
2024-03-28
初识RPC
初识RPC介绍RPC 是远程过程调用的简称,是分布式系统中不同节点间流行的通信方式。在互联网时代,RPC 已经和 IPC 一样成为一个不可或缺的基础构件。因此 Go 语言的标准库也提供了一个简单的 RPC 实现,我们将以此为入口学习 RPC 的各种用法。 hello RPC server端代码 12345678910111213141516171819202122232425262728293031package mainimport ( "log" "net" "net/rpc")type HelloService struct{}func (p *HelloService) Hello(request string, reply *string) error { *reply = "hello:" + request return nil}func main() { rpc.RegisterName("HelloService"...
评论
