Prometheus源码:服务发现
Prometheus源码:服务发现
服务发现的定义
流程:
scrape发现服务进行统一管理,Prometheus对所支持的发 现服务都抽象出Discoverer接口,各scrape发现服务都必须实现该接 口并用于服务发现
Discover接口定义了Run()接口:
1 | // FILE Path:prometheus/discovery/discovery |
所有的服务都会转换为
1 | // File Path: prometheus/discovery/targetgroup/targetgroup.go |
启动manager
服务管理都在manager.go中启动
1 | // File Path:prometheus/discovery/manager.go |
manager的定义:
1 | // File Path:prometheus/discovery/manager.go |
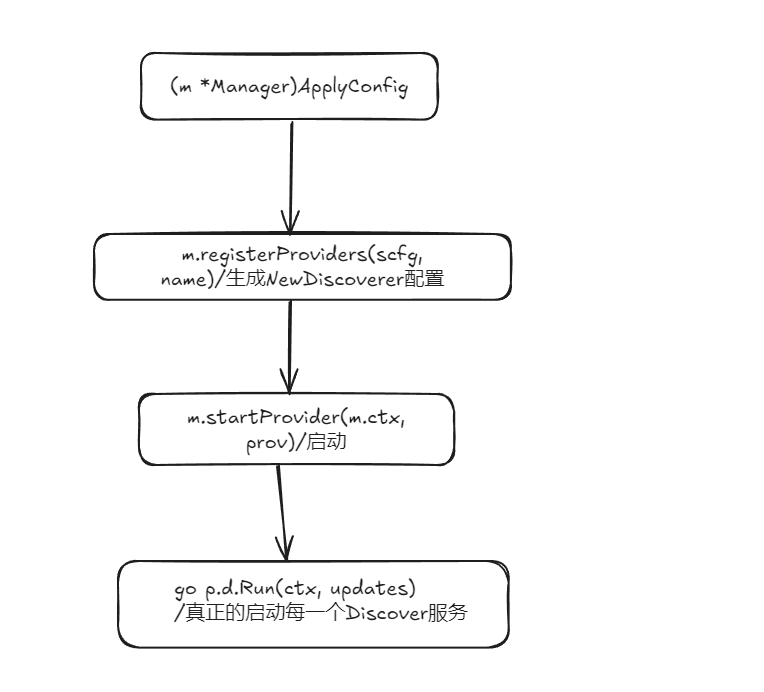
构建启动服务发现
Prometheus 在初始化过程中会构建 discoveryManagerScrape, 并通过调用ApplyConfig方法完成对Discoverer的构建:
1 | // File Path:prometheus/discovery/manager.go |
推送消息给discover服务者
1 | // consul 实现 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Joohwan!
 alipay
alipay
相关推荐

2025-09-24
Prometheus源码-Relabel
Prometheus源码-Relabel 基于3.5 relabel address流程 Prometheus读取Job中的targets,把target赋值给__address__标签,此标签代表采集地址 将__address__赋值给__param_target标签,因为Promehrues访问采集地址需要传参,__param_target代表target参数 将__param_target标签赋值给instance标签 将__param_target替换为真实的采集地址 核心解析Label Re123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114// Popul...
2025-08-05
Prometheus-PromQL
Prometheus-PromQL 基于v3.5 工作原理graph TD A[Query Input] --> B[Parser] B --> C[Engine] C --> D[Query Execution] D --> E[Result Output] %% Parser Module subgraph Parser["Parser (parser/)"] B1[Lexical Analysis] --> B2[Syntax Parsing] B2 --> B3[AST Generation] B3 --> B4[Validation] end %% Engine Module subgraph Engine["Engine (engine.go)"] C1[Query Initialization] --> C2[Query Planning]...
2025-07-26
Prometheus-Rules告警评估
Prometheus-Rules告警评估 基于v3.5 工作原理graph TD A[Rule Files] --> B[Manager.LoadGroups] B --> C[Parse Rule Groups] C --> D[Create Rule Objects] D --> E[Analyse Rule Dependencies] E --> F[Build Dependency Map] F --> G[Set Rule Dependencies] H[Manager.Run] --> I[Group Evaluation Loop] I --> J[Split Rules into Batches] J --> K{Concurrent Evaluation Enabled?} K -->|Yes| L[Concurrent Rule Execution] K -->|No| M[S...
2025-07-25
Prometheus-Scrape指标抓取
Prometheus-Scrape指标抓取 基于v3.5 工作原理graph TD A[ScrapePool] --> B[Target Discovery] A --> C[Scrape Loop Management] A --> D[HTTP Client] B --> B1[Sync Targets] B1 --> B2[Target Group Processing] B2 --> B3[Target Creation/Deduplication] B3 --> B4[Active Targets Update] C --> C1[Loop Creation] C1 --> C2[Scrape Interval Setup] C2 --> C3[Scraper Initialization] D --> D1[Target Scraper] D1 --> D2[HTTP Request] D2 --> D3[Metrics Endpoint] C3 -->...
2025-07-24
Prometheus-notifier告警推送
Prometheus-notifier告警推送 基于v3.5 工作原理sequenceDiagram participant Q as Queue participant M as Manager participant AM as Alertmanager participant AL as Alertmanager API Q->>M: nextBatch() M->>M: 分批处理告警 M->>AM: sendAll() AM->>AM: 应用特定于 AM 的 relabel AM->>AL: HTTP POST /api/v2/alerts AL-->>AM: Response AM->>M: 返回发送结果 关键特性 告警队列管理 有界队列,防止内存无限增长 支持队列满时的丢弃策略 可配置的批处理大小 Relabeling(重新标记) 发送前对告警应用 relabel 配置 支持每个 Alertmanager 集合的特定 relabel 规则 高可用性...
2025-07-23
Prometheus-Discoverer服务发现
Prometheus-Discoverer服务发现 基于v3.5 启动流程sequenceDiagram participant main.go participant Manager participant Provider participant Discoverer participant TargetGroup main.go->>Manager: NewManager() main.go->>Manager: ApplyConfig() Manager->>Provider: 创建Provider实例 Manager->>Provider: startProvider() Provider->>Discoverer: 初始化具体发现器(如K8s/Consul等) Provider->>Discoverer: Run(ctx, updatesCh) loop 发现循环 Discoverer->>TargetGroup: 获取目标组 ...
评论
