Prometheus源码:启动
Prometheus源码:启动
基于release-3.0
目录结构
- cmd主程序入口
- config 默认配置参数设置及配置文件解析
- discovery 服务发现方式的实现,如 consul ,kubernetes ,dns 等
- notifier 生成告警信息及告警信息发送
- promql 目录为 规则计算的具体实现,根据载入的规则进行规则计算,并生成告警配置
- prompb 目录定义了三种协议,远程存储协议、rpc通信协议和types协议
- scrape 指标采集
- relabel 目录实现了对指标维度(label)的重置处理,根据promtheus.yaml中配置文件中relabel_config配置项内容重置指标维度
- retrieval 目录为Prometheus的数据采集模块,实现了对采集服务的调度和对指标数据的采集
- rules 目录为Prometheus的规则管理模块,用于实现规则加载、计算调度和告警信息的回调;
- storage 目录为Prometheus的指标存储模块,又remote、tsdb存储俩种
- tsdb 数据存储相关
- web 目录是 Prometheus Web服务模块
组件启动
存储组件
localStorage 用于指标的本地存储;remoteStorage 用于指标的 远程存储;fanoutStorage为localStorage与remoteStorage的读写代 理器,且remoteStorage可以有多个传入,如下所示:
1 | var ( |
notifier组件
notifier组件用于告警通知,在完成初始化后,notifier组件内 部 会 构 建 一 个 告 警 通 知 队 列 , 队 列 的 大 小 由 命 令 行 参 数 – alertmanager.notification-queue-capacity确定,默认值为10000, 且告警信息通过sendAlerts方法发送给AlertManager
1 | notifierManager = notifier.NewManager(&cfg.notifier, log.With(logger, "component", "notifier")) |
discoveryManagerScrape组件
discoveryManagerScrape 组 件 用 于 发 现 指 标 采 集 服 务 , 对 应 prometheus.yml配置文件中scrape_configs节点下的各种指标采集器 (static_config、kubernetes_sd_config、openstack_sd_config、 consul_sd_config 等
1 | discMgr := discovery.NewManager(ctxScrape, log.With(logger, "component", "discovery manager scrape"), prometheus.DefaultRegisterer, sdMetrics, discovery.Name("scrape")) |
discoveryManagerNotify组件
discoveryManagerNotify组件的构建与 discoveryManagerScrape 组件的构建方式一样,不同的是前者服务于 notify,后者服务于 scrape
1 | { |
scrapeManager组件
scrapeManager组件用于管理对指标的采集,并将所采集的指标存 储到fanoutStorage中。
scrapeManager组件的采集周期在prometheus.yml配置文件中由 global 节 点 下 的 scrape_interval 指 定 , 且 各 个 job_name 可 以 在 scrape_configs 下 进 行 个 性 化 设 置 , 设 置 符 合 自 身 应 用 场 景 的 scrape_interval
1 | discMgr := legacymanager.NewManager(ctxScrape, log.With(logger, "component", "discovery manager scrape"), prometheus.DefaultRegisterer, sdMetrics, legacymanager.Name("scrape")) |
queryEngine组件
queryEngine 组件为规则查询计算引擎,在初始化时会对查询超时时间 ( cfg.query Timeout ) 和并发查询个数 (cfg.queryEngine.MaxConcurrentQueries)进行设置。 queryEngine 组件的构建调用 promql.NewEngine 方法完成, fanoutStorage 为指标存储器,cfg.queryEngine为组件对应的配置参数
1 | queryEngine = promql.NewEngine(opts) |
ruleManager组件
ruleManager组件整合了 fanoutStorage组件、queryEngine组件 和 notifier组件,完成了从规则运算到告警发送的流程。
规则运算周期在 prometheus.yml 配置文件中由 global 节点下 的 evaluation_interval 指 定 , 各个job_name 还 可 以 在 scrape_configs下进行个性化设置,设置符合自身应用场景的规则运 算周期(evaluation_interval)
1 | ruleManager = rules.NewManager(&rules.ManagerOptions{ |
启动服务组件
将各个组件服务的启动入口,通过github.com/oklog/oklog/pkg/group中的Add方法
Add方法如下:
1 | func (g *Group) Add(execute func() error, interrupt func(error)) { |
最后通过Run()启动
1 | if err := g.Run(); err != nil { |
Run()的实现:
1 | func (g *Group) Run() error { |
一共十个Add():
- 第一个:Add用于控制 Prometheus程序的退出。当满足以下任一 条件时将退出:Prometheus接收到 SIGTERM系统信号;Prometheus程 序设置了–web.enable-lifecycle参数来启动且收到curl -X POST localhost:9090/-/quit请求
- 第二个:用于启动discoveryManagerScrape服务。
- 第三个:用于启动discoveryManagerNotify服务
- 第四个:根据在第2个 Add中 discoveryManagerScrape发现 的 scrape服务启动且采集指标数据
- 第五个:系统配置的热加载,reloadConfig方法用于加载 系统配置文件,且当 Prometheus 进程收到 SIGHUP 信号或者收到 curl -X POST localhost:9090/-/reload请求(Prometheus启动参数- -web.enable-lifecycle)时,reloadConfig方法会被调用
- 第六个:用于初始化系统配置的参数和设置Web可用的服务状 态
- 第七个:启动存储组件,Prometheus 指标的存储采用的是 时序数据库,所以在初始化启动时会设置开始时间和储存路径
- 第八个:用于启动Web服务组件
- 第九个:用于启动规则管理组件ruleManager
- 第十个:根据在第3个 Add 中 discoveryManagerNotify 发现的AlertManager启动notifier组件服务
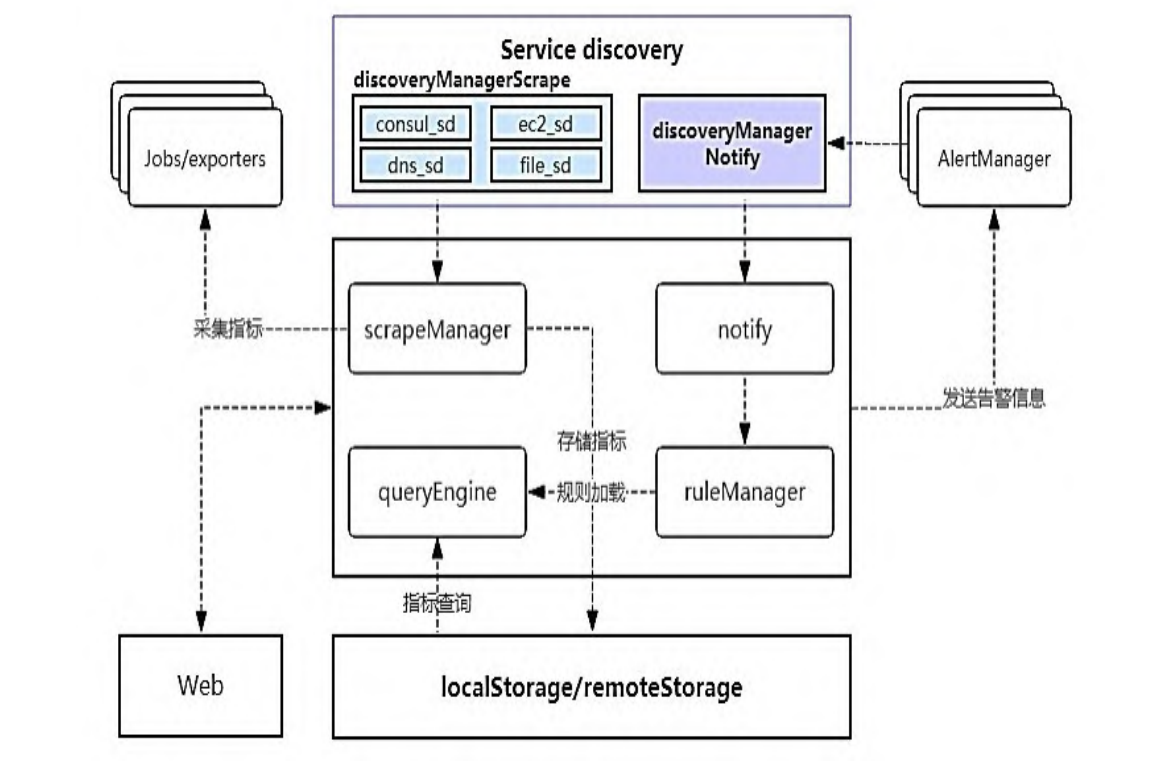
组件关系如图:
 alipay
alipay

