func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).InfoS("computePodActions got for pod", "podActions", podContainerChanges, "pod", klog.KObj(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.ErrorS(err, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf(ref, v1.EventTypeNormal, events.SandboxChanged, "Pod sandbox changed, it will be killed and re-created.")
} else {
klog.V(4).InfoS("SyncPod received new pod, will create a sandbox for it", "pod", klog.KObj(pod))
}
}
if podContainerChanges.KillPod {
if podContainerChanges.CreateSandbox {
klog.V(4).InfoS("Stopping PodSandbox for pod, will start new one", "pod", klog.KObj(pod))
} else {
klog.V(4).InfoS("Stopping PodSandbox for pod, because all other containers are dead", "pod", klog.KObj(pod))
}
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if killResult.Error() != nil {
klog.ErrorS(killResult.Error(), "killPodWithSyncResult failed")
return
}
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
klog.V(3).InfoS("Killing unwanted container for pod", "containerName", containerInfo.name, "containerID", containerID, "pod", klog.KObj(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, containerInfo.reason, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.ErrorS(err, "killContainer for pod failed", "containerName", containerInfo.name, "containerID", containerID, "pod", klog.KObj(pod))
return
}
}
}
m.pruneInitContainersBeforeStart(pod, podStatus)
var podIPs []string
if podStatus != nil {
podIPs = podStatus.IPs
}
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
klog.V(4).InfoS("Creating PodSandbox for pod", "pod", klog.KObj(pod))
metrics.StartedPodsTotal.Inc()
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
sysctl.ConvertPodSysctlsVariableToDotsSeparator(pod.Spec.SecurityContext)
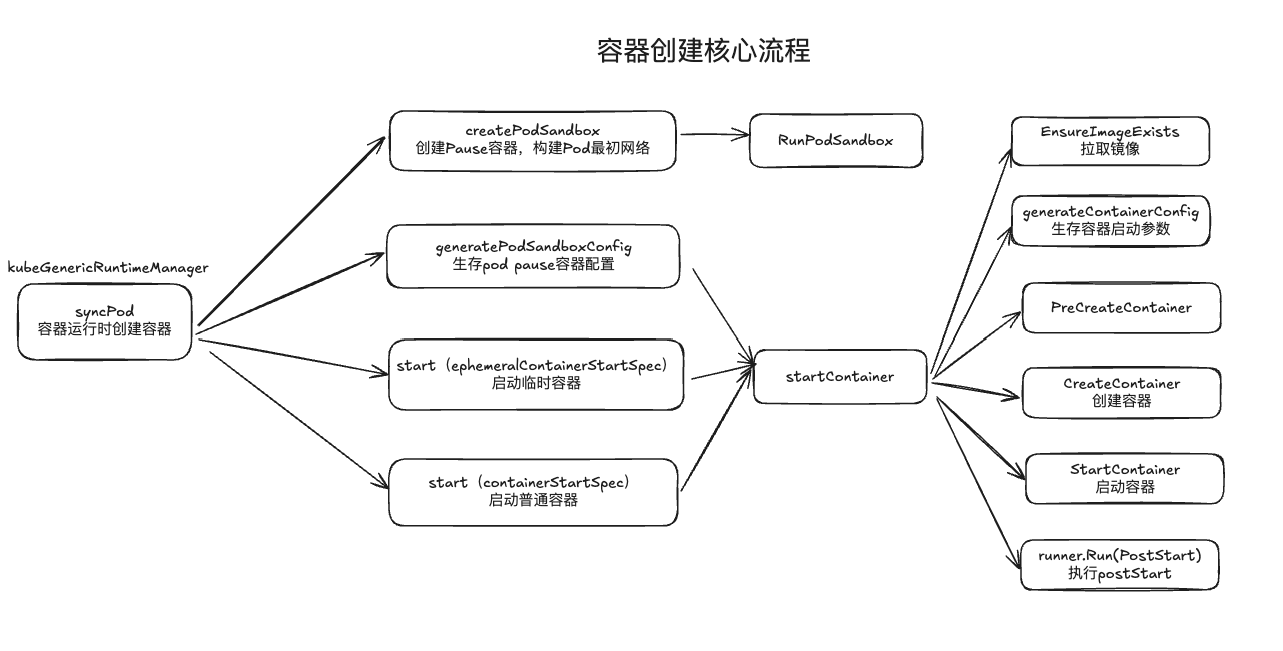
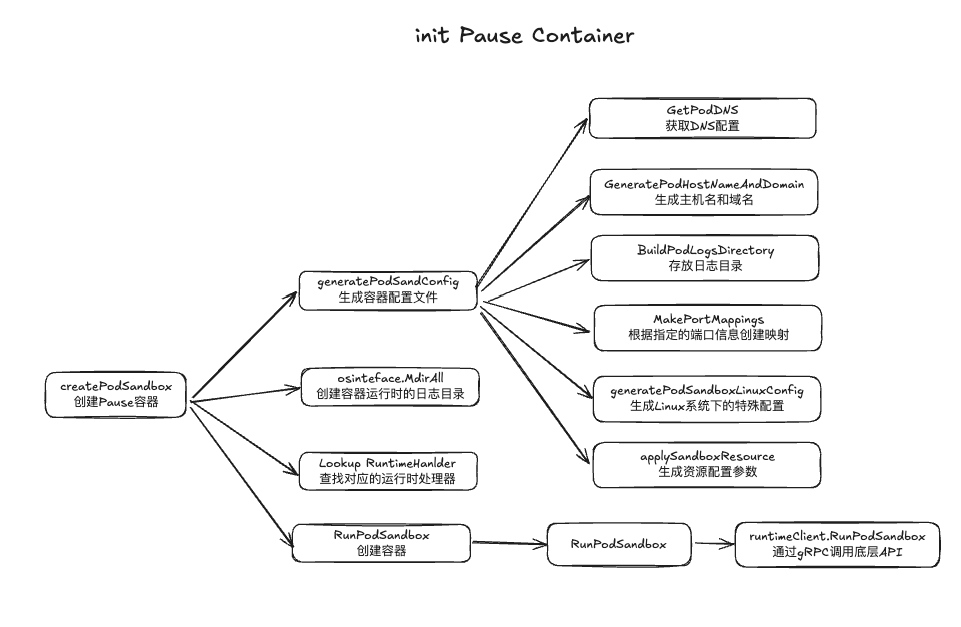
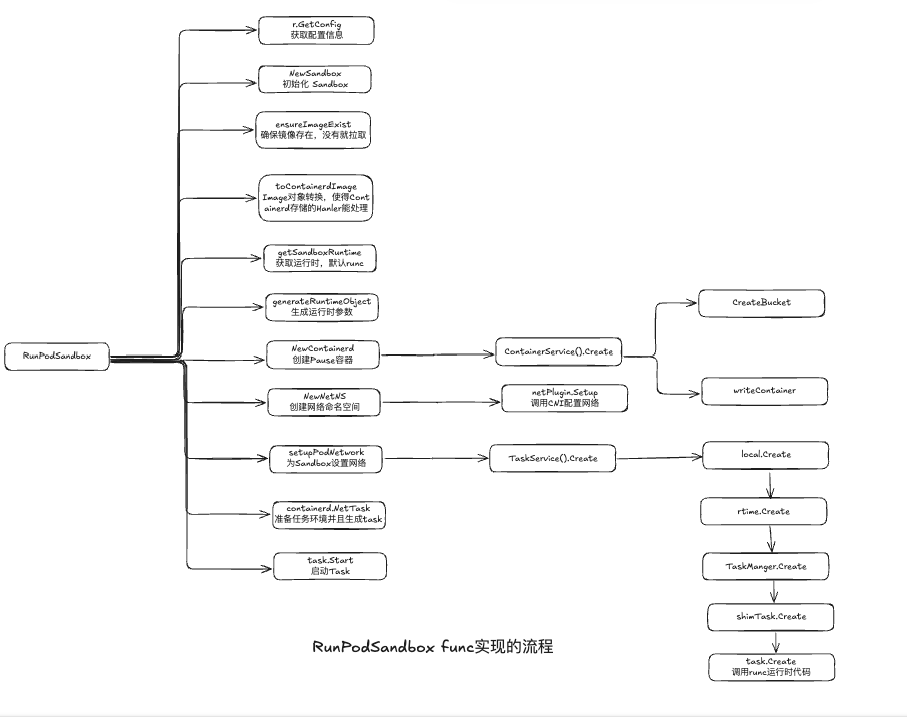
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
if m.podStateProvider.IsPodTerminationRequested(pod.UID) {
klog.V(4).InfoS("Pod was deleted and sandbox failed to be created", "pod", klog.KObj(pod), "podUID", pod.UID)
return
}
metrics.StartedPodsErrorsTotal.Inc()
createSandboxResult.Fail(kubecontainer.ErrCreatePodSandbox, msg)
klog.ErrorS(err, "CreatePodSandbox for pod failed", "pod", klog.KObj(pod))
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.ErrorS(referr, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedCreatePodSandBox, "Failed to create pod sandbox: %v", err)
return
}
klog.V(4).InfoS("Created PodSandbox for pod", "podSandboxID", podSandboxID, "pod", klog.KObj(pod))
resp, err := m.runtimeService.PodSandboxStatus(podSandboxID, false)
if err != nil {
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.ErrorS(referr, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedStatusPodSandBox, "Unable to get pod sandbox status: %v", err)
klog.ErrorS(err, "Failed to get pod sandbox status; Skipping pod", "pod", klog.KObj(pod))
result.Fail(err)
return
}
if resp.GetStatus() == nil {
result.Fail(errors.New("pod sandbox status is nil"))
return
}
if !kubecontainer.IsHostNetworkPod(pod) {
podIPs = m.determinePodSandboxIPs(pod.Namespace, pod.Name, resp.GetStatus())
klog.V(4).InfoS("Determined the ip for pod after sandbox changed", "IPs", podIPs, "pod", klog.KObj(pod))
}
}
podIP := ""
if len(podIPs) != 0 {
podIP = podIPs[0]
}
configPodSandboxResult := kubecontainer.NewSyncResult(kubecontainer.ConfigPodSandbox, podSandboxID)
result.AddSyncResult(configPodSandboxResult)
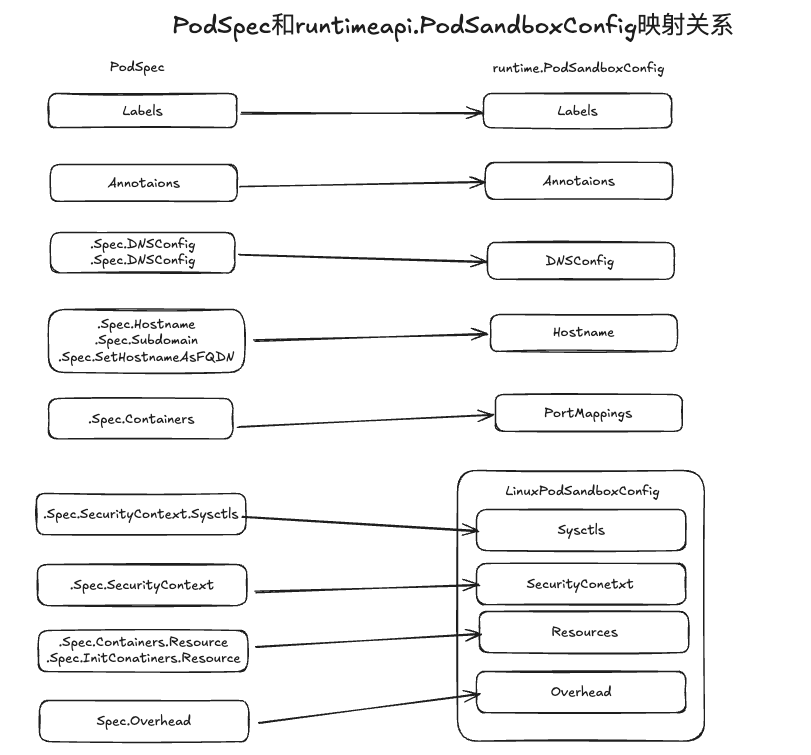
podSandboxConfig, err := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
if err != nil {
message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err)
klog.ErrorS(err, "GeneratePodSandboxConfig for pod failed", "pod", klog.KObj(pod))
configPodSandboxResult.Fail(kubecontainer.ErrConfigPodSandbox, message)
return
}
start := func(typeName, metricLabel string, spec *startSpec) error {
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, spec.container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, spec.container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
klog.V(4).InfoS("Backing Off restarting container in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod))
return err
}
metrics.StartedContainersTotal.WithLabelValues(metricLabel).Inc()
if sc.HasWindowsHostProcessRequest(pod, spec.container) {
metrics.StartedHostProcessContainersTotal.WithLabelValues(metricLabel).Inc()
}
klog.V(4).InfoS("Creating container in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod))
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, spec, pod, podStatus, pullSecrets, podIP, podIPs); err != nil {
metrics.StartedContainersErrorsTotal.WithLabelValues(metricLabel, err.Error()).Inc()
if sc.HasWindowsHostProcessRequest(pod, spec.container) {
metrics.StartedHostProcessContainersErrorsTotal.WithLabelValues(metricLabel, err.Error()).Inc()
}
startContainerResult.Fail(err, msg)
switch {
case err == images.ErrImagePullBackOff:
klog.V(3).InfoS("Container start failed in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod), "containerMessage", msg, "err", err)
default:
utilruntime.HandleError(fmt.Errorf("%v %+v start failed in pod %v: %v: %s", typeName, spec.container, format.Pod(pod), err, msg))
}
return err
}
return nil
}
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", metrics.EphemeralContainer, ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
if container := podContainerChanges.NextInitContainerToStart; container != nil {
if err := start("init container", metrics.InitContainer, containerStartSpec(container)); err != nil {
return
}
klog.V(4).InfoS("Completed init container for pod", "containerName", container.Name, "pod", klog.KObj(pod))
}
for _, idx := range podContainerChanges.ContainersToStart {
start("container", metrics.Container, containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
|
 alipay
alipay
