K8s工作负载-Deployment
K8s工作负载-Deployment
基于1.25
什么是Deployment
Deployment 最常见就是部署无状服务,缩写Deploy
- Deployment实现声明的方法控制Pod和ReplicaSet
- 支持滚定升级和回滚应用
- 支持扩容和缩容
- 暂停和继续Deployment
DeploymentSpec
// DeploymentSpec is the specification of the desired behavior of the Deployment. |
PodTempldate
PodTempldate是K8s顶级资源对象
// PodTemplateSpec describes the data a pod should have when created from a template |
DeploymentStragegy
DeploymentStragegy包含俩个字段
type:部署类型
- Recreate:重建
- RollingUpdate:回滚升级,默认
RollingUpdate:只有RollingUpdate才有
// DeploymentStrategy describes how to replace existing pods with new ones. |
设置MaxUnavailable=0,MaxSugre=1。每次先启动一个新Pod,才会删除一个旧的Pod,服务滚动过程比较平滑。不影响业务
计算MaxUnavailable和MaxSurge
- MaxUnavailable和MaxSurge俩个func计算
- 内部都调用ResovleFenceposts,同时返回俩个值
- ResovleFenceposts内部调用GetScaledValueFromIntOrPercent func进行解析
- 如果是数字直接返回
- 如果是百分比和总副本数相除,根据传入参数向上或者向下取整
- 如果俩个值为0,MAxUnavailable设置为0
-
// MaxUnavailable returns the maximum unavailable pods a rolling deployment can take.
func MaxUnavailable(deployment apps.Deployment) int32 {
if !IsRollingUpdate(&deployment) || *(deployment.Spec.Replicas) == 0 {
return int32(0)
}
// Error caught by validation
_, maxUnavailable, _ := ResolveFenceposts(deployment.Spec.Strategy.RollingUpdate.MaxSurge, deployment.Spec.Strategy.RollingUpdate.MaxUnavailable, *(deployment.Spec.Replicas))
if maxUnavailable > *deployment.Spec.Replicas {
return *deployment.Spec.Replicas
}
return maxUnavailable
}
...
// MaxSurge returns the maximum surge pods a rolling deployment can take.
func MaxSurge(deployment apps.Deployment) int32 {
if !IsRollingUpdate(&deployment) {
return int32(0)
}
// Error caught by validation
maxSurge, _, _ := ResolveFenceposts(deployment.Spec.Strategy.RollingUpdate.MaxSurge, deployment.Spec.Strategy.RollingUpdate.MaxUnavailable, *(deployment.Spec.Replicas))
return maxSurge
}
...
// ResolveFenceposts resolves both maxSurge and maxUnavailable. This needs to happen in one
// step. For example:
//
// 2 desired, max unavailable 1%, surge 0% - should scale old(-1), then new(+1), then old(-1), then new(+1)
// 1 desired, max unavailable 1%, surge 0% - should scale old(-1), then new(+1)
// 2 desired, max unavailable 25%, surge 1% - should scale new(+1), then old(-1), then new(+1), then old(-1)
// 1 desired, max unavailable 25%, surge 1% - should scale new(+1), then old(-1)
// 2 desired, max unavailable 0%, surge 1% - should scale new(+1), then old(-1), then new(+1), then old(-1)
// 1 desired, max unavailable 0%, surge 1% - should scale new(+1), then old(-1)
// Ref:https://github.com/kubernetes/kubernetes/blob/88e994f6bf8fc88114c5b733e09afea339bea66d/pkg/controller/deployment/util/deployment_util.go#L841C1-L870C1
func ResolveFenceposts(maxSurge, maxUnavailable *intstrutil.IntOrString, desired int32) (int32, int32, error) {
surge, err := intstrutil.GetScaledValueFromIntOrPercent(intstrutil.ValueOrDefault(maxSurge, intstrutil.FromInt(0)), int(desired), true)
if err != nil {
return 0, 0, err
}
unavailable, err := intstrutil.GetScaledValueFromIntOrPercent(intstrutil.ValueOrDefault(maxUnavailable, intstrutil.FromInt(0)), int(desired), false)
if err != nil {
return 0, 0, err
}
if surge == 0 && unavailable == 0 {
// Validation should never allow the user to explicitly use zero values for both maxSurge
// maxUnavailable. Due to rounding down maxUnavailable though, it may resolve to zero.
// If both fenceposts resolve to zero, then we should set maxUnavailable to 1 on the
// theory that surge might not work due to quota.
unavailable = 1
}
return int32(surge), int32(unavailable), nil
}
滚动更新
Deployment 的滚动更新本质上是新旧版本的ReplicaSet完成的,更新分成Scale Up和Scale Down
- Scale Up:新的RelicaSet朝着
deployment.Spec.Replicas指定的数据递增 - Scale Down:旧的RelicaSetrplicas朝着0递减
- 一次完整的滚动更新,需要经历多次的Scale Up和Scale Down
新旧RS不是通过创建时间区分,而是调用EqualIgnoreHash Func实现,把rs.Spec.Template 和 deployment.Spec.Template 进行对比
rs.Spec.Template和deployment.Spec.Template进行对比
找到一致,设置为新的RS,找不到一致,新建新的RS
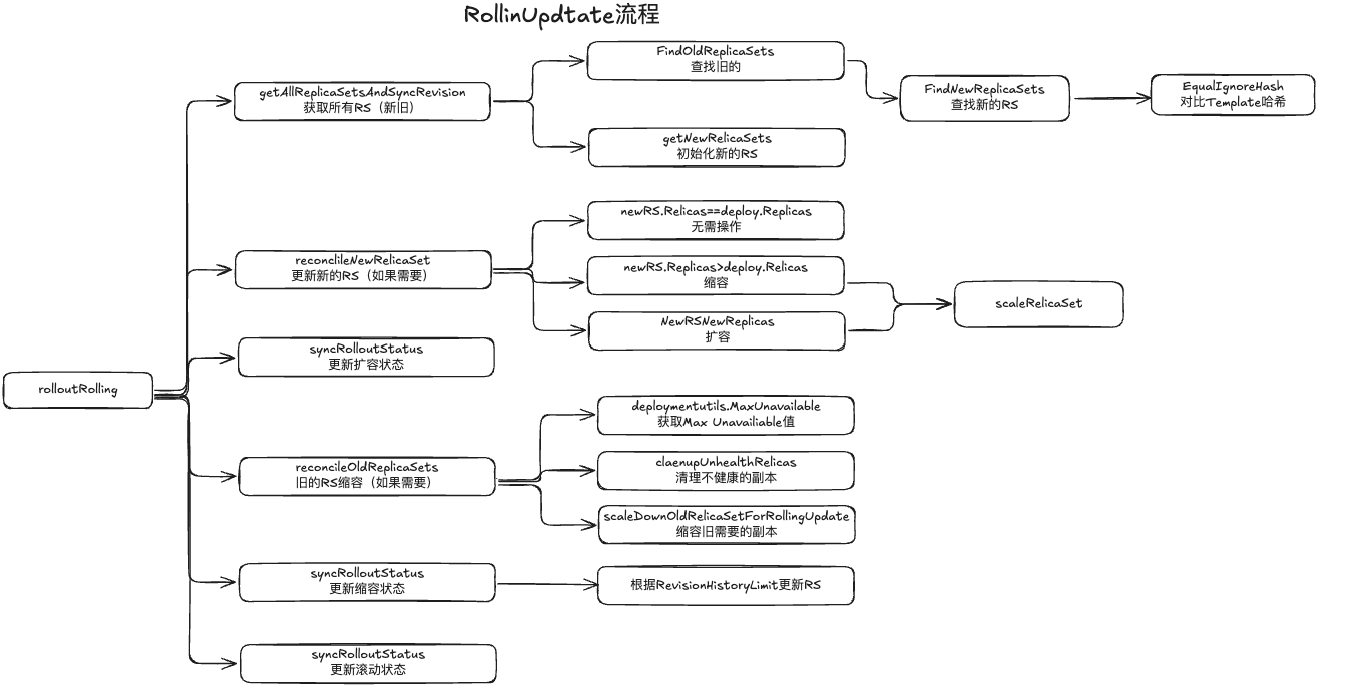
Scale Up
// NewRSNewReplicas calculates the number of replicas a deployment's new RS should have. |
Scale Down
缩容的场景有俩种:
- 旧的副本有一些不健康,用户为了安全的缩容健康的副本
- 如果心的副本集已经扩大,副本准备就绪
- Ref:https://github.com/kubernetes/kubernetes/blob/88e994f6bf8fc88114c5b733e09afea339bea66d/pkg/controller/deployment/rolling.go#L87
func (dc *DeploymentController) reconcileOldReplicaSets(ctx context.Context, allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment) (bool, error) { |
重新创建更新策略
重新创建重新更新测策略:把旧的RS中Pod全部删除,再创建心等待RS中的Pod
scaleDownOldReplicaSetsForRecreate:把旧的RS,内部调用scaleReplicaSetAndRecordEvent,传入新副本数0.即全部缩容scaleUpNewReplicationSetForRecreate:负责创建新的RS,内部调用scaleReplicaSetAndRecordEvent,传入新的副本数量Deployment中RS,全部创建新的Pod更新完成,清理历史RS,最多保留
spec.RevisionHistoryLimit个历史版本更新Deployment状态,执行kubectl describe查看滚动更新信息
-
// rolloutRecreate implements the logic for recreating a replica set.
func (dc *DeploymentController) rolloutRecreate(ctx context.Context, d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID][]*v1.Pod) error {
// Don't create a new RS if not already existed, so that we avoid scaling up before scaling down.
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
// scale down old replica sets.
scaledDown, err := dc.scaleDownOldReplicaSetsForRecreate(ctx, activeOldRSs, d)
if err != nil {
return err
}
if scaledDown {
// Update DeploymentStatus.
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
// Do not process a deployment when it has old pods running.
if oldPodsRunning(newRS, oldRSs, podMap) {
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
// If we need to create a new RS, create it now.
if newRS == nil {
newRS, oldRSs, err = dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, true)
if err != nil {
return err
}
allRSs = append(oldRSs, newRS)
}
// scale up new replica set.
if _, err := dc.scaleUpNewReplicaSetForRecreate(ctx, newRS, d); err != nil {
return err
}
if util.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(ctx, oldRSs, d); err != nil {
return err
}
}
// Sync deployment status.
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
MinReadySeconds
MinReadySeconds的作用是在Scale Up的过程中,新创建的Pod处于Ready状态的基础上,等待MinReadySeconds才被认为可用状态
- 防止新建Pod发生崩溃,在更新过程,影响服务可用性
 alipay
alipay

