K8s工作负载-ReplicaSet
K8s工作负载-ReplicaSet
基于1.25
什么是ReplicaSet
ReplicaSet的为指定Pod维护一个副本数量的集合,缩写RS
- 一般新版本,用户不直接操作RS
- 通过Deployment的生命周期,来管理RS
ReplicaSetSpec
1 | // ReplicaSetSpec is the specification of a ReplicaSet. |
同步副本操作
RS控制器负责调谐RS状态
- manageReplicas func是核心实现,完成同步副本调用
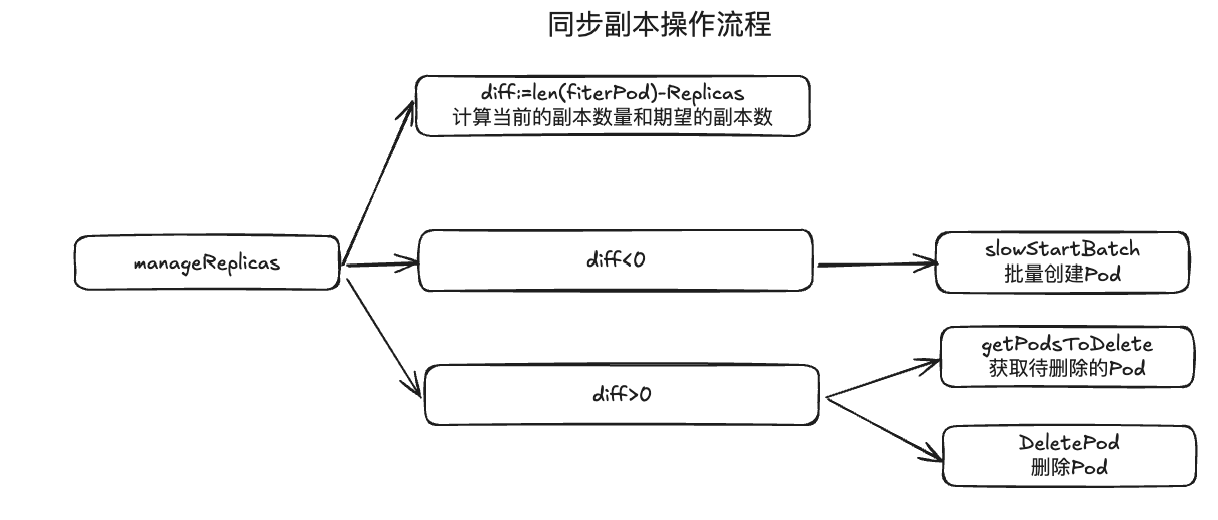
1 | // manageReplicas checks and updates replicas for the given ReplicaSet. |
慢启动批量创建Pod
slowStartBatch func:实现并发创建Pod
- 从一组的initialBatchSize 开始,默认1
- 按照1,2,4,8 指数增大创建Pod
- 如果出现任何失败,当前批次完成后,跳过所有剩余批次,返回成功调用次数
- Ref:https://github.com/kubernetes/kubernetes/blob/88e994f6bf8fc88114c5b733e09afea339bea66d/pkg/controller/replicaset/replica_set.go#L759
1 | // slowStartBatch tries to call the provided function a total of 'count' times, |
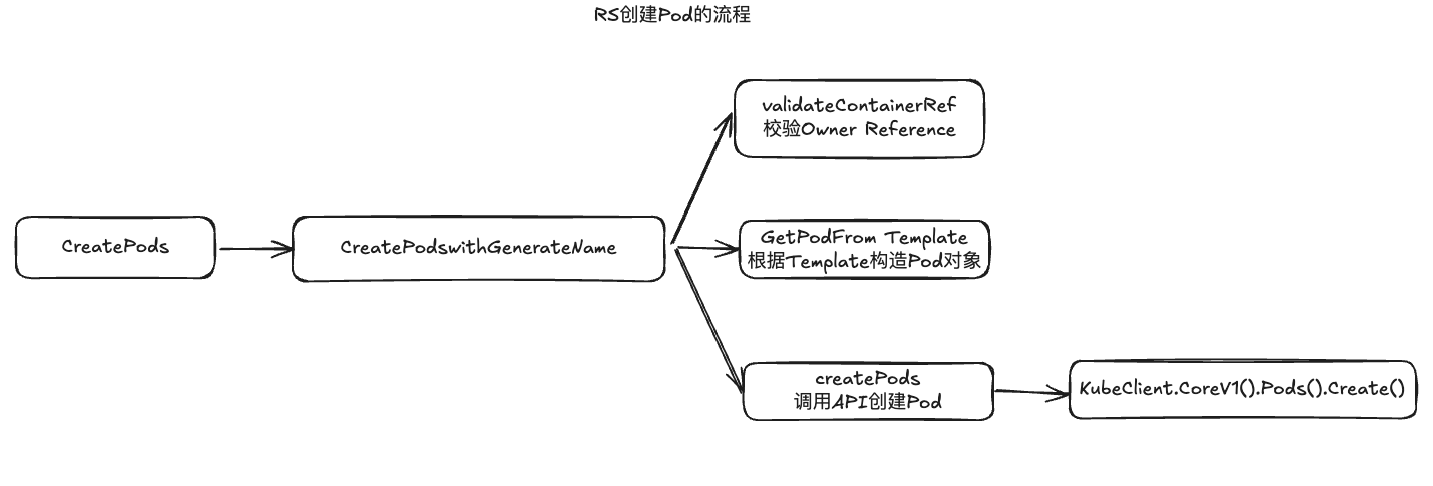
创建Pod的流程
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Joohwan!
 alipay
alipay
相关推荐

2026-03-22
K8s-CSI卷挂载流程
CSI 存储卷挂载通信流程目标这篇文档只回答一个核心问题:kubelet 如何通过 CSI (Container Storage Interface) 完成 Pod 存储卷的挂载? 重点放在 VolumeManager 与 CSI driver 的交互,以及 attach/mount 的完整流程。 一句话摘要kubelet 的 VolumeManager 通过 CSINode 和 CSIDriver 对象发现 CSI driver,然后通过 gRPC 调用 CSI driver 的 NodeStageVolume/NodePublishVolume 完成卷的挂载。 1. 流程总览从通信视角看,这条链路可以拆成 3 个阶段: 卷准备阶段:CSI controller 完成 attach (对于块存储)。 节点挂载阶段:kubelet 通过 CSI driver 完成 stage 和 publish。 容器挂载阶段:kubelet 将卷 bind mount 到容器内。 架构总览图flowchart TB subgraph 控制面["控制面...
2026-03-22
K8s-DNS解析流程
DNS 解析流程本文档描述 Kubernetes 集群中 CoreDNS 如何解析 Service 到 Pod IP 的完整流程。 概述Kubernetes DNS 解析涉及以下核心组件: CoreDNS:集群 DNS 服务器 kube-dns Service:指向 CoreDNS Pod 的 Service EndpointSlice:记录 CoreDNS Pod 的 IP 地址 Pod /etc/resolv.conf:Pod 内的 DNS 配置 flowchart TD subgraph Pod["Pod (应用容器)"] A["应用发起 DNS 查询"] B["读取 /etc/resolv.conf"] end subgraph CoreDNS["CoreDNS Pod"] C["CoreDNS 服务"] D["Watch API Server&quo...
2026-03-22
K8s-Deployment滚动更新流程
Deployment 滚动更新流程本文档描述 Kubernetes Deployment 如何通过 ReplicaSet Controller 管理滚动更新的完整流程。 概述Deployment 滚动更新涉及以下核心组件: Deployment Controller:管理 Deployment 生命周期 ReplicaSet Controller:管理 Pod 副本数 API Server:存储和分发资源状态 flowchart TD subgraph User["用户操作"] A["kubectl apply -f deployment.yaml"] end subgraph APIServer["API Server"] B["Deployment 资源"] C["ReplicaSet 资源"] D["Pod 资源"] end subgraph D...
2026-03-22
K8s-EndpointSlice控制器流程
EndpointSlice 控制器流程本文档描述 Kubernetes EndpointSlice 控制器如何让 Service 感知后端 Pod 变化的完整流程。 概述EndpointSlice 控制器负责: 监听 Service 和 Pod 变化 生成和管理 EndpointSlice 资源 记录 Service 后端 Pod 的 IP 地址和端口 flowchart TD subgraph APIServer["API Server"] A["Service 资源"] B["Pod 资源"] C["EndpointSlice 资源"] D["Node 资源"] end subgraph EndpointSliceController["EndpointSlice Controller"] E["Watch Service"] ...
2026-03-22
K8s-PVC供应与绑定流程
PVC 供应与绑定流程本文档描述 Kubernetes 中 PVC(PersistentVolumeClaim)、PV(PersistentVolume)和 StorageClass 的完整交互流程。 概述PVC 供应与绑定涉及以下核心组件: PV Controller:管理 PV 和 PVC 的绑定 StorageClass:定义动态供应参数 Provisioner:实际创建存储卷(in-tree 或 CSI) Scheduler:处理 WaitForFirstConsumer 模式 flowchart TD subgraph User["用户操作"] A["创建 PVC"] end subgraph APIServer["API Server"] B["PVC 资源"] C["PV 资源"] D["StorageClass"] end subgra...
2026-03-22
K8s-Pod在节点落地流程
Pod 在节点落地通信流程目标这篇文档只回答一个核心问题:kubelet 如何把“期望运行”的 Pod 变成“真实运行”的容器? 重点放在 kubelet 内部各组件之间的协作与 CRI 通信边界,而不是每一个 gRPC 字段的含义。 一句话摘要kubelet 收到 Pod 更新后,把期望态交给 podWorkers;podWorkers 驱动单 Pod 生命周期状态机,再由 kubeGenericRuntimeManager 通过 CRI 调用容器运行时完成 sandbox、镜像与容器操作。 1. 流程总览从通信视角看,这条链路可以拆成 3 个阶段: 更新接入阶段:kubelet 从 Pod source 收到属于本节点的 Pod 更新,并交给内部子系统。 状态机驱动阶段:podWorkers 根据当前状态决定执行同步、终止还是清理。 运行时执行阶段:runtime manager 通过 CRI 把操作翻译给容器运行时,完成 sandbox 和容器的创建/销毁。 Mermaid:总览图flowchart LR A[Pod update from sour...
评论
